Con un nombre de producto cual detergente anunciado en TV tenemos una solución de HA y Multi-Master que deja en pañales en cuanto a senzillez de configuración, mantenimiento y resolución de incidencias (troubleshooting) a la infraestructura sobre la que hablamos hace poco en éste post acerca de DRBD + Pacemaker + Corosync (aunque está claro que ésta última es multipurpose, y no sólo orientada a un servicio en particular). Estamos hablando del Percona XtraDB Cluster, una solución opensource (GPLv2) de HA y cluster escalable para MySQL que integra la librería Galera y le añade una serie de herramientas propias.
Como hemos dejado entrever, Percona nos ofrece un setup rápido y senzillo para montar una infraestructura Multi-Master de N nodos MySQL. Lo que viene a traducirse a que podemos usar cualquier nodo tanto para leer como para escribir en paralelo, encargándose de gestionar el acceso en simultáneo a un mismo recurso. Ésto nos da la opción de definir un buen abanico de arquitecturas, como por ejemplo:
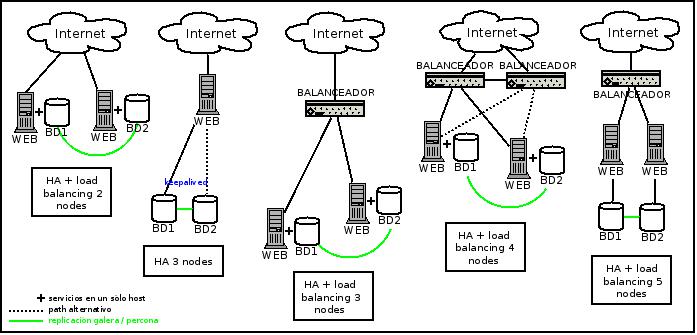
Elegir una u otra ya depende de las necesidades/presupuesto de cada cual. El setup que vamos a comentar aquí es el correspondiente al segundo gráfico, dónde un host accede a uno de los 2 nodos que forman el Percona XtraDB Cluster. Si bien para Percona ambos estan en modo Master (siendo viable atacar a cualquiera de ellos para leer, escribir o ambos en un momento dado), haremos que sólo uno actúe a la vez, quedando el otro de reserva/backup. Es decir, vamos a simular un entorno Master-Slave. ¿Por qué íbamos a hacer eso pudiendo aprovecharnos de un entorno Multi-Master? Porque deseamos disponer de un entorno de HA por encima del load balancing, teniendo un nodo en producción y el otro en replicación constante, y si algo le sucediera al que está en producción poder poner el otro en su lugar (y que todo siga funcionando). Y éste comportamiento lo lograremos configurando una ip virtual con Keepalived que será la que definirá el nodo en producción, estando el otro de reserva pero con todos los datos actualizados al momento.
Comentar también que si bien en todo momento sólo hablamos de clusters de 2 nodos, en realidad pueden ser los que se deseen. De hecho, Percona/Galera recomiendan un setup mínimo de 3 para evitar encontrarse con situaciones de split brain, de las cuales no se encarga el cluster. Esto nos lleva a recomendar que en previsión del posible crecimiento del número de nodos que forma el cluster, éste funcione por Multicast para evitar saturar el ancho de banda de los equipos de red. Ésto también lo veremos aquí, así que vamos al lio.
Instalación de Percona XtraDB Cluster y configuración básica
- Añadimos la key y el repositorio de paquetes para Debian de Percona y actualizamos la lista de paquetes. Nótese que sustituimos convenientemente VERSION por nuestra versión de Debian (creo que actualmente sólo hay paquetes para squeeze y wheezy):
- Instalamos Percona y paramos el servicio:
- A continuación, configuramos el nodo primario (el que hará el bootstrap/inicialización del cluster) y lo iniciamos:
- Breve explicación de algunos de los parámetros de la configuración del punto anterior:
- wsrep_cluster_address: Inicialmente indicamos el string de conexión vacío/sin direcciones ip (gcomm://) para inicializar (bootstrapping) el cluster y una vez esté formado, debemos sustituirla por la cadena (comentada con ###) que tiene todas las direcciones ip correspondientes a los nodos del cluster.
- default_storage_engine: Motor de BD por defecto. Recomendable -aunque no obligatorio- usar InnoDB. Actualmente la replicación también funciona con MyISAM, con sus limitaciones intrínsecas (bloqueo a nivel de tabla).
- wsrep_node_address: Dirección ip de éste nodo.
- wsrep_sst_method: método SST (State Snapshow Transfer), o cómo son transferidos los datos cuando un nodo se une al cluster. Puede ser vía mysqldump, rsync y xtrabackup, éste último el más conveniente por no requerir READ LOCK.
- wsrep_cluster_name: Nombre del cluster.
- wsrep_sst_auth: Autenticación (usuario:contraseña) para unir nodos al cluster.
- Hacemos un check del cluster para ver su estado:
- En el mismo nodo, creamos el usuario que se usará para hacer el SST (State Snapshot Transfer):
- Ahora configuramos el nodo secundario y lo iniciamos. Es posible que dé un error al iniciar el servicio, en cuyo caso tenemos que cerciorarnos que la contraseña para el usuario que gestiona el servicio en Debian (debian-sys-maint) sea la misma que la del nodo primario (/etc/mysql/debian.cnf):
- Finalmente hacemos un check del cluster en éste mismo nodo:
$ apt-key adv --keyserver keys.gnupg.net --recv-keys 1C4CBDCDCD2EFD2A $ vi /etc/apt/sources.list.d/percona.list deb http://repo.percona.com/apt VERSION main deb-src http://repo.percona.com/apt VERSION main $ apt-get update
$ apt-get install percona-xtradb-cluster-server-5.5 percona-xtradb-cluster-client-5.5 $ /etc/init.d/mysql stop
$ vi /etc/mysql/my.cnf [mysqld] datadir=/var/lib/mysql user=mysql # Path to Galera library wsrep_provider=/usr/lib/libgalera_smm.so # Empty gcomm address is being used when cluster is getting bootstrapped wsrep_cluster_address=gcomm:// # Cluster connection URL contains the IPs of node#1 and node#2 ###wsrep_cluster_address=gcomm://192.168.0.61,192.168.0.62 # In order for Galera to work correctly binlog format should be ROW binlog_format=ROW # MyISAM storage engine has only experimental support default_storage_engine=InnoDB # This is a recommended tuning variable for performance innodb_locks_unsafe_for_binlog=1 # This changes how InnoDB autoincrement locks are managed and is a requirement for Galera innodb_autoinc_lock_mode=2 # Node #1 address wsrep_node_address=192.168.0.61 # SST method wsrep_sst_method=xtrabackup # Cluster name wsrep_cluster_name=my_percona_cluster # Authentication for SST method wsrep_sst_auth="sstuser:s3cretPass" $ /etc/init.d/mysql start
mysql@percona1> show status like 'wsrep%'; +----------------------------+--------------------------------------+ | Variable_name | Value | +----------------------------+--------------------------------------+ | wsrep_local_state_uuid | b598af3e-ace3-11e2-0800-3e90eb9cd5d3 | ... | wsrep_local_state | 4 | | wsrep_local_state_comment | Synced | ... | wsrep_cluster_size | 1 | | wsrep_cluster_status | Primary | | wsrep_connected | ON | ... | wsrep_ready | ON | +----------------------------+--------------------------------------+ 40 rows in set (0.01 sec)
Fijémonos que el parámetro wsrep_cluster_size nos indica que efectivamente es el primer nodo que conforma el cluster.
mysql@percona1> CREATE USER 'sstuser'@'localhost' IDENTIFIED BY 's3cretPass'; mysql@percona1> GRANT RELOAD, LOCK TABLES, REPLICATION CLIENT ON *.* TO 'sstuser'@'localhost'; mysql@percona1> FLUSH PRIVILEGES;
$ vi /etc/mysql/my.cnf [mysqld] datadir=/var/lib/mysql user=mysql # Path to Galera library wsrep_provider=/usr/lib/libgalera_smm.so # Cluster connection URL contains IPs of node#1 and node#2 wsrep_cluster_address=gcomm://192.168.0.61,192.168.0.62 # In order for Galera to work correctly binlog format should be ROW binlog_format=ROW # MyISAM storage engine has only experimental support default_storage_engine=InnoDB # This is a recommended tuning variable for performance innodb_locks_unsafe_for_binlog=1 # This changes how InnoDB autoincrement locks are managed and is a requirement for Galera innodb_autoinc_lock_mode=2 # Node #2 address wsrep_node_address=192.168.0.62 # Cluster name wsrep_cluster_name=my_percona_cluster # SST method wsrep_sst_method=xtrabackup #Authentication for SST method wsrep_sst_auth="sstuser:s3cretPass" $ /etc/init.d/mysql start
mysql@percona2> show status like 'wsrep%'; +----------------------------+--------------------------------------+ | Variable_name | Value | +----------------------------+--------------------------------------+ | wsrep_local_state_uuid | b598af3e-ace3-11e2-0800-3e90eb9cd5d3 | ... | wsrep_local_state | 4 | | wsrep_local_state_comment | Synced | ... | wsrep_cluster_size | 2 | | wsrep_cluster_status | Primary | | wsrep_connected | ON | ... | wsrep_ready | ON | +----------------------------+--------------------------------------+ 40 rows in set (0.01 sec)
De nuevo, el parámetro wsrep_cluster_size nos indica que ahora tenemos 2 nodos en el cluster. El wsrep_local_state_uuid nos dará (para ir bien) un id del cluster que coincidirá con el previo. Para cada nodo a añadir al cluster seguiremos los pasos 1, 2, 7 y 8.
Con ésto ya tenemos el cluster de 2 nodos MySQL montado y funcionando por Unicast. Referencia: Percona Ubuntu Howto
Configuración del Multicast.
- Primero debemos comprobar que el tráfico Multicast esté permitido en nuestra red. Hay muchas maneras de hacerlo, a continuación se usa iperf para averiguarlo:
- Si el test fue correcto, debemos añadir primero una interfaz de red (p.ej. eth1) que se encargará del tráfico Multicast:
- Posteriormente definiremos una nueva variable a la configuración de MySQL que le indicará la ip Multicast que usaremos, tras lo cual reiniciaremos por separado (núnca a la vez) cada nodo:
- Para comprobar que todo fue bien, podemos monitorizar éste tráfico (UDP) en cada nodo para esa ip del grupo Multicast:
root@percona2:~# iperf -s -u -B 226.94.1.1 -i 1 ------------------------------------------------------------ Server listening on UDP port 5001 Binding to local address 226.94.1.1 Joining multicast group 226.94.1.1 Receiving 1470 byte datagrams UDP buffer size: 122 KByte (default) ------------------------------------------------------------ [ 3] local 226.94.1.1 port 5001 connected with 212.11.66.254 port 49525 [ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams [ 3] 0.0- 1.0 sec 128 KBytes 1.05 Mbits/sec 0.037 ms 0/ 89 root@percona1:~# iperf -c 226.94.1.1 -u -T 32 -t 3 -i 1 ------------------------------------------------------------ Client connecting to 226.94.1.1, UDP port 5001 Sending 1470 byte datagrams Setting multicast TTL to 32 UDP buffer size: 122 KByte (default) ------------------------------------------------------------ [ 3] local 212.11.66.254 port 49525 connected with 226.94.1.1 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0- 1.0 sec 129 KBytes 1.06 Mbits/sec
# Adición manual/temporal para salir del caso: $ ifconfig eth1 up $ ip ro add dev eth1 224.0.0.0/4 # O adición permanente, preferible para evitar olvidos al reiniciar: $ vi /etc/network/interfaces auto eth1 iface eth1 inet manual up ifconfig eth1 up post-up route add -net 224.0.0.0/24 dev eth1
$ vi /etc/mysql/my.cnf wsrep_provider_options = "gmcast.mcast_addr=239.192.0.11" $ /etc/init.d/mysql restart
$ tcpdump -n udp host 239.192.0.11
Aplicaremos ésta configuración en cada nodo del cluster siguiendo los mismos pasos.
Instalación y configuración de Keepalived + indicador de rol en prompt.
Como hemos comentado con anterioridad, Keepalived nos servirá para definir quién es el nodo Master y quién el Slave en base a una ip virtual (usaremos la 192.168.0.60) que migrará de un nodo a otro en función de su disponibilidad. Esto lo hará usando su capacidad de failover gracias a la gestión del protocolo VRRP. A parte, también crearemos un script que nos proporcionará una identificación visual rápida/cómoda a través de un string coloreado en el prompt (con M para Master o S para Slave) para saber qué nodo está actuando con qué rol con sólo conectarnos.
- Instalamos Keepalived, lo configuramos y reiniciamos el servicio:
- Creamos el script que gestionará el cambio de prompt y le damos permisos de ejecución:
- Añadimos la llamada al script al inicio de sesión:
- Para finalizar, reiniciamos Keepalived y salimos/entramos a la sesión:
$ apt-get install keepalived
$ vi /etc/keepalived/keepalived.conf
vrrp_instance PERCONA {
interface eth0
# Equidad de preferencia en los nodos
state EQUAL
# Identificador para la comunicación de los nodos por VRRP
virtual_router_id 123
priority 10
virtual_ipaddress {
# Ip virtual que definirá el nodo Master
192.168.0.60/24 label eth0:60
}
# Script lanzado a cada cambio de estado
notify /usr/sbin/prompt.sh
}
$ vi /usr/sbin/prompt.sh
#!/bin/bash
msg (){
if [ "$TERM" = "xterm" ]; then
case "$1" in
"Slave")
echo -e '\e[0;33m(S)\e[0m'
;;
"Master")
echo -e '\e[0;32m(M)\e[0m'
;;
*)
echo -e '\e[0;35m(U)\e[0m'
esac
else
if [ -n "$1" ]; then echo $1
else echo "Unknown"
fi
fi
}
ifconfig | grep "192.168.0.60" &>/dev/null
if [ $? -eq 0 ]; then msg Master
else msg Slave
fi
$ chmod +x /usr/sbin/prompt.sh
$ vi /root/.bashrc PS1='\u@\h:\w`prompt.sh`\$ '
$ /etc/init.d/keepalived restart $ exit
Esto cabe hacerlo en cada nodo del cluster. Con ésto bien configurado, seran los prompts los que nos indiquen quién es Master y quién Slave. Si tuviéramos 2 hosts del cluster distintos (p.ej. uno más potente que otro), podríamos definir para el potente una mayor priority para forzar que éste sea el nodo Master preferido siempre que esté disponible.
Popourri
- Procotolos y puertos. Por si usamos firewalls, conviene tener presente que usaremos los protocolos TCP, UDP (para el Multicast) y VRRP (para Keepalived). Los puertos, a parte del de MySQL (3306) son el 4444, 4567 y 4568.
- Monitorización. Se podria hacer un script para Nagios (o cualquier otro sistema de monirorización) que tomara en cuenta el valor que devuelven las siguientes variables en cada uno de los nodos que forman el cluster (con una consulta como la que vimos antes, show status like 'wsrep%';):
wsrep_cluster_size - Nombre de nodos del cluster (ojo porque existe algún BUG con éste parámetro) wsrep_cluster_status - Indica si todos los nodos del cluster estan sincronizados (Primary) o hay alguno en situación de split brain wsrep_ready - Indica si el cluster está listo o si por el contrario, no puede recibir comandos SQL. wsrep_connected - Indica si el nodo está o no conectado al cluster. wsrep_flow_control_paused - Indica el estado de sincronización del cluster (si tiene o no lag).
Comentarios (2)