En este post veremos cómo montar una plataforma de HA en MySQL con arquitectura Master-Slave. ¿Cómo conseguir esto? Pues para describirlo brevemente, por un lado, con un gestor de recursos en clúster (Pacemaker) y una capa de mensajería entre sus nodos (Corosync), y por otro, con una tecnología de "RAID1 por red" (DRBD) en sustitución de las capacidades de clúster de MySQL (es decir, éste no sabrá que está en clúster). En realidad estas herramientas dan para mucho más que montar algo como lo que haremos a continuación, pero nosotros nos quedaremos aquí (al menos, de momento).
Antes de pasar a la acción, vamos a describir el proyecto que tenemos en mente y algunas opciones de montaje. Y para ello, nada mejor que unas figuras para visualizar los 3 tipos de arquitectura que podemos configurar con este número de nodos (unos 4-5):
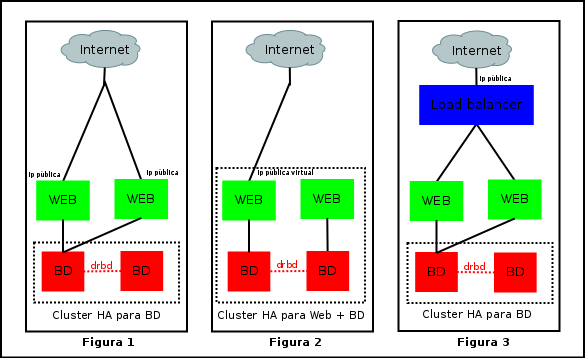
La primera (Figura 1) define 2 servidores web con la misma configuración sirviendo los mismos contenidos y atacando a la misma base de datos (en clúster), pero funcionan independientemente y por ello cada uno tiene una ip pública propia. Esto evidentemente no puede definirse HA; el balanceo se haría a nivel de dns (2 registros A). Si uno falla, tendremos problemas. Dependiendo del navegador, si éste es medianamente moderno no tendremos la mala suerte de perder el 50% de los requests que van al servidor caído porque -y esto es experiencia personal- su estrategia es esperar un tiempo prudencial (<1 minuto) y si no hubo suerte en la carga del request del primer registro A, redirigirá la petición al otro y acabaría cargando el contenido. La mala noticia es que en el mundo web, cuando tenemos tiempos de carga superiores a los 15-20 segundos... hay una gran probabilidad que el visitante desista.
La segunda arquitectura (Figura 2) ya es otra cosa. En este caso también lo tenemos todo redundado (a nivel de servidores, ojo), con la diferencia que el clúster vigila no sólo la disponibilidad de la base de datos, sino también del servidor web, de modo que si uno de estos 2 servicios cae, se mueve todo al segundo (incluyendo la ip virtual compartida).
La tercera arquitectura (Figura 3) es otro modo de ofrecer ésta redundancia web, con la diferencia de que quien gestiona su disponibilidad normalmente también sabe repartirla y aprovechamos una característica adicional: el balanceo de carga (p.ej. con Zen Load Balancer, LVS, Apache mod_proxy_server, etc). Aunque éste sería el mejor escenario de los 3, vamos a desarrollar el segundo que bastante chicha tiene ya éste tema. Y posteriormente, cuando tengamos todo digerido, siempre podemos movernos hacia la figura del balanceador.
Así pues, he aquí el gráfico definitivo que ilustra cómo va a quedar el asunto sería algo como lo siguiente:
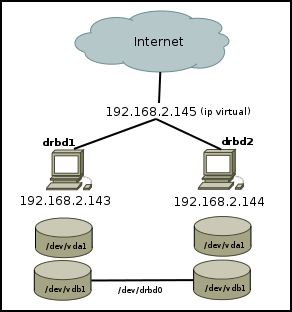
Los equipos mostrados (2) son destinados únicamente a la parte de base de datos (aunque posteriormente podemos añadirle la parte web) y comparten una ip virtual (192.168.2.145). También podemos apreciar que cada uno tiene 2 particiones: la principal para / y la otra para montar la parte de los datos de MySQL (que ubicaremos en la ruta original, /var/lib/mysql). Por el nombre de los discos, puede verse que estoy operando con máquinas virtuales KVM, aunque esto carece de interés para nuestro propósito.
Al lío y por pasos:
- Configuramos las direcciones ip y los hostnames (ponerlos también en /etc/hosts):
debian1# echo "drbd1" > /etc/hostname debian2# echo "drbd2" > /etc/hostname drbd1# vi /etc/network/interfaces: auto eth0 iface eth0 inet static address 192.168.2.143 netmask 255.255.255.0 gateway 192.168.2.1 drbd2# vi /etc/network/interfaces: auto eth0 iface eth0 inet static address 192.168.2.144 netmask 255.255.255.0 gateway 192.168.2.1 # vi /etc/hosts: 192.168.2.143 drbd1 192.168.2.144 drbd2
- Generamos y ubicamos las respectivas llaves ssh en cada host:
drbd1# ssh-keygen drbd2# ssh-keygen drbd1# ssh-copy-id root@drbd2 drbd2# ssh-copy-id root@drbd1
- Instalamos los siguientes paquetes en ambos nodos (el ntpd es para drbd):
# apt-get install drbd-utils pacemaker ntpdate
- Quitamos el autostart de DRBD en ambos nodos porque los gestionará Pacemaker. Esto es una norma general para todos los recursos que sean gestionados por el clúster para que no se inicien mas que cuando deban. Adicionalmente, habilitarlo para Corosync:
# update-rc.d -f drbd remove # echo "START=yes" > /etc/default/corosync drbd1# scp /etc/default/corosync drbd2:/etc/default/corosync
- Configuramos DRBD en ambos nodos:
# vi /etc/drbd.conf: include "drbd.d/global_common.conf";
# vi /etc/drbd.d/global_common.conf: global { usage-count no; } common { syncer { # Max. sync rate (couple bandwitdh with harddisk performance). rate 10M; } } resource srv { device /dev/drbd0; disk /dev/vdb1; flexible-meta-disk internal; # Synchronous replication protocol. protocol C; handlers { # Notify when splitbrain happens. split-brain "/usr/lib/drbd/notify-split-brain.sh root"; # Called if node is primary, degraded and local copy of the data is inconsistent. pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; # Node is primary but lost the after-split-brain auto recovery procedure. As a consequence, it should be abandoned. pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; # DRBD got an IO error from the local IO subsystem. local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f"; } startup { outdated-wfc-timeout 110; degr-wfc-timeout 120; } disk { # Disk error handling. On disk errors, DRBD will automatically use the other node, even if this can cause a performance penalty. on-io-error detach; } net { cram-hmac-alg sha1; shared-secret "EldersOfTheInternet1"; # Lines dedicated to handle split-brain situations (e.g. if one of the nodes fails). after-sb-0pri discard-zero-changes; # If both nodes are secondary, just make one of them primary. after-sb-1pri discard-secondary; # If one is primary, one is not, trust the primary node. after-sb-2pri call-pri-lost-after-sb; # If there are two primaries, make the unchanged one secondary. rr-conflict disconnect; } syncer { al-extents 257; } on drbd1 { address 192.168.2.143:7788; } on drbd2 { address 192.168.2.144:7788; } } - Cargamos el módulo del kernel drbd, nos aseguramos que lo haga a cada inicio y arrancamos DRBD para comprobar que funciona y se sincroniza:
# modprobe drbd # echo "drbd" >> /etc/modules # /etc/init.d/drbd start # Si dió errores, probar: drbdadm create-md srv # drbd-overview ó cat /proc/drbd
- Hacemos que uno de los nodos DRBD sea primario, creamos un filesystem, lo montamos, instalamos MySQL, le quitamos el autoarranque, comprobamos que inicie y posteriormente lo paramos junto con DRBD:
drbd1# drbdadm primary all drbd1# mkfs.ext4 /dev/drbd0 drbd1# mkdir /var/lib/mysql drbd1# mount -t ext4 /dev/drbd0 /var/lib/mysql drbd1# apt-get install mysql-server drbd1# /etc/init.d/mysql stop drbd1# chmod mysql.mysql /var/lib/mysql drbd1# update-rc.d -f mysql remove drbd1# /etc/init.d/mysql start drbd1# /etc/init.d/mysql stop drbd1# /etc/init.d/drbd stop drbd2# mkdir /var/lib/mysql drbd2# apt-get install mysql-server drbd2# update-rc.d -f mysql remove drbd2# /etc/init.d/mysql stop drbd2# rm -rf /var/lib/mysql/* drbd2# /etc/init.d/drbd stop # Esto de a continuación es importante para conservar el usuario que administra el servicio en Debian drbd1# scp /etc/mysql/debian.cnf drbd2:/etc/mysql/debian.cnf
- Configuramos Corosync:
# vi /etc/corosync/corosync.conf: totem { # Version of the configuration file. version: 2 # How long before declaring a token lost (ms). token: 3000 # How many token retransmits before forming a new configuration. token_retransmits_before_loss_const: 10 # How long to wait for join messages in the membership protocol (ms). join: 60 # How long to wait for consensus to be achieved before starting a new round of membership configuration (ms). consensus: 3600 # Turn off the virtual synchrony filter. vsftype: none # Number of messages that may be sent by one processor on receipt of the token. max_messages: 20 # Limit generated nodeids to 31-bits (positive signed integers). clear_node_high_bit: yes # Disable encryption (faster). secauth: off # How many threads to use for encryption/decryption. threads: 0 # This specifies the mode of redundant ring, which may be none, active, or passive. rrp_mode: none interface { # The following values need to be set based on your environment. ringnumber: 0 # The address of the network in which totem will route traffic. bindnetaddr: 192.168.2.0 # Multicast address used by corosync executive (default is ok). mcastaddr: 226.94.1.1 # UDP port number. mcastport: 5405 } } service { # Load the Pacemaker Cluster Resource Manager. ver: 0 name: pacemaker } logging { fileline: off to_stderr: yes to_logfile: yes logfile: /var/log/corosync/corosync.log to_syslog: yes syslog_facility: daemon debug: off timestamp: on } - Iniciamos corosync y comprobamos el estado inicial del cluster:
drbd1# /etc/init.d/corosync start drbd2# /etc/init.d/corosync start # crm_mon -1 ó crm status
- Configuramos el clúster con crm:
drbd1# crm configure property stonith-enabled="false" drbd1# corosync-keygen # A continuación descargamos algo 'gordo' para generar entropía más rápido drbd1# wget https://www.kernel.org/pub/linux/kernel/v3.x/testing/linux-3.10-rc3.tar.xz drbd1# scp /etc/corosync/authkey drbd2:/etc/corosync/authkey drbd1# crm configure # Entering crm interactive prompt...
# Creamos un resource de tipo "drbd" y definimos los parámetros (el nombre del recurso en la config. de drbd es "srv" y los tiempos de los checks para cada nodo). primitive drbd_mysql ocf:linbit:drbd params drbd_resource="srv" op monitor interval="29s" role="Master" op monitor interval="31s" role="Slave" # Creamos un resource de tipo "Filesystem" y definimos sus parámetros. primitive fs_mysql ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/var/lib/mysql" fstype="ext4" # Creamos un resource de tipo "IPaddr2" y definimos sus parámetros. primitive ip_mysql ocf:heartbeat:IPaddr2 params ip="192.168.2.145" nic="eth0:0" # Creamos un resource del tipo mysql (sin parámetros). primitive mysqld lsb:mysql # Creamos el grupo "mysql" que une los resources: fs_mysql ip_mysql mysqld. Los inicia secuencialmente y los apaga del mismo modo, pero en orden inverso. group mysql fs_mysql ip_mysql mysqld # Creamos un resource del tipo clon multi-state del recurso "drbd_mysql". Permite a las múltiples instancias estar en uno de ambos modos de operación: Master y Slave, iniciándose ésta -el clon- en estado Slave. ms ms_drbd_mysql drbd_mysql meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true" # Definimos un colocation constraint para forzar que el grupo "mysql" se ejecute en el mismo nodo dónde el recurso "ms_drbd_mysql:Master" esté activo. colocation mysql_on_drbd inf: mysql ms_drbd_mysql:Master # Definimos un order constraint para forzar que tengamos el recurso DRBD promovido a Master previo a iniciar MySQL en él. order mysql_after_drbd inf: ms_drbd_mysql:promote mysql:start property $id="cib-bootstrap-options" expected-quorum-votes="2" stonith-enabled="false" no-quorum-policy="ignore" rsc_defaults $id="rsc-options" resource-stickiness="100" migration-threshold="3" exit
Un inciso para comentar que ésta herramienta tiene muchas opciones que podemos ir descubriendo a medida que lo necesitemos. Comandos inmediatamente necesarios pueden ser los siguientes:
- crm status|crm_mon para consultar el estado del clúster.
- crm configure show para mostrar la configuración.
- crm node show para mostrar el estado de los nodos que forman el clúster.
- crm node standby|online para poner un nodo en mantenimiento o de vuelta a producción.
- crm ra list para ver una lista de los resource agents (los scripts que usa Pacemaker para interactuar con los servicios).
- Como en nuestro clúster sólo usamos 2 nodos, modificamos la configuración de quorum en el cluster para ajustar la gestión de fallos:
# crm configure property expected-quorum-votes="1" # crm configure property no-quorum-policy="ignore"
- (Opcional) Si quisiéramos añadir Apache2 a la ecuación para terminar consiguiendo lo descrito en la Figura 2, añadiríamos algo como lo siguiente:
drbd1# apt-get install apache2 drbd1# update-rc.d -f apache2 remove drbd2# apt-get install apache2 drbd2# update-rc.d -f apache2 remove # crm configure primitive apache ocf:heartbeat:apache params configfile=/etc/apache2/apache2.conf op monitor interval="30s" # crm configure colocation apache_on_drbd inf: apache ms_drbd_mysql:Master # crm configure order apache_after_drbd inf: ms_drbd_mysql:promote apache:start
Que en definitiva viene a añadir la gestión de Apache2 con un archivo de configuración dado, la ubicación para que se ejecute en el mismo nodo dónde esté levantado el DRBD en modo Master y el orden para que se lance una vez el nodo DRBD haya sido promovido a Master.
Nota final: Esta configuración ha sido probada satisfactoriamente en Debian 6 y posteriormente migrada a Debian 7, donde también funciona a pesar de la actualización a versiones superiores de Corosync y Pacemaker.
Referencias imprescindibles:
MySQL high availability cluster with DRBD+Pacemaker/Corosync Building HA cluster with Pacemaker, Corosync and DRBD Clusters from Scratch
Comentarios (7)