Con este título que bien podría ser el de uno de los libros de la editorial WIley (un besito para esos mochalbetes!), resumo en unos breves pasos lo que cabe hacer si se quieren servir torrents en todo su esplendor. Desde nuestro SO favorito (of course, GNU/Linux) y desde linea de comando.
Para hablar con algo más de propiedad, debemos separar los datos/archivos a compartir propiamente (archivos de texto, música, documentos...), de los archivos .torrent, que son los que definen cosas como qué se comparte, dónde está el tracker, en cuántos 'chuncks' y de qué tamaño son éstos, etc...
Software necesario:
- createtorrent. Su nombre es bastante intuitivo. Nos permitirá crear ficheros (binarios) .torrent. Como hace un par de dias que la veo caída, os dejó aquí el tarball para que podáis igualmente llegar al valhala.
- opentracker. Aunque su nombre puede confundir a más de uno con el de algún tipo de software para componer canciones (trackers), esta vez el tracking se refiere al de torrents (y sus seeds/peers). Es decir, será quien publique la información del .torrent y quien lleve la trazade quién lo tiene, etc...
- rtorrent, ctorrent, etc... El cliente de torrent para CLI que os haga más rabia.
Pasos:
- Bajamos los sources del CVS de opentracker, lo compilamos (junto a la libreria que necesita, libowfat) y le creamos un fichero de inicio y configuración como este (que podéis poner en /etc/init.d/) para hacer su uso más ameno y poder gestionarlo cual servicio. Es suficiente con seguir las senzillas instrucciones de descarga cvs y compilación de la web. Tened en cuenta que el make install pone el binario (lo único necesario) en un directorio por encima del de compilación. Éste tiene el nombre de bin, que podemos renombrar convenientemente a opentracker-bin y ponerlo en /sbin/.
- Bajamos (el tarball de) createtorrent, también lo compilamos y creamos nuestro primer .torrent teniendo en cuenta los settings de publicación que pusimos en la configuración de opentracker. Un enemplo de uso acorde con la configuración de opentracker anterior sería:
createtorrent -a http://torrents.dominio.com documento_de_ejemplo.pdf documento_de_ejemplo.torrent
- En la linea anterior, el subdominio torrents.dominio.com debe estar apuntando a la ip cuya interfaz pusimos a escuchar opentracker (ver el switch i de mi script opentracker), y después van los parámetros con el archivo de datos y el archivo .torrent a crear, que deberá crearse o ubicarse en el directorio controlado por opentracker: /torrents/ en nuestro caso. Ya podemos iniciar el tracker con un /etc/init.d/opentracker-bin start para que empiece a servir nuestro primer .torrent.
- Finalmente, iniciamos nuestro cliente de torrents CLI preferido (desde cualquier ubicación que tenga visibilidad de nuestro opentracker) apuntando a un directorio que contenga tanto el .torrent como el archivo de datos. Con esto pretendemos que el cliente detecte que ya dispone del archivo al completo y se registre en el tracker como seeder, para servirlo a los demás (es necesario al menos uno, no basta con tener únicamente un tracker!).
- Con esto y si todo está bien (aplicaciones ejecutándose, configuraciones que tocan), ya podemos hacer la prueba de usar otro cliente de torrent desde otra máquina y cargar el .torrent que generamos, para ver si nos hablamos con el tracker y si se nos transmite el fichero de datos.
A parte de esto, al software necesario podríamos añadir un servidor web como medio de distribución de los ficheros .torrent, pero su configuración se sale fuera del propósito y alcance de éste artículo.
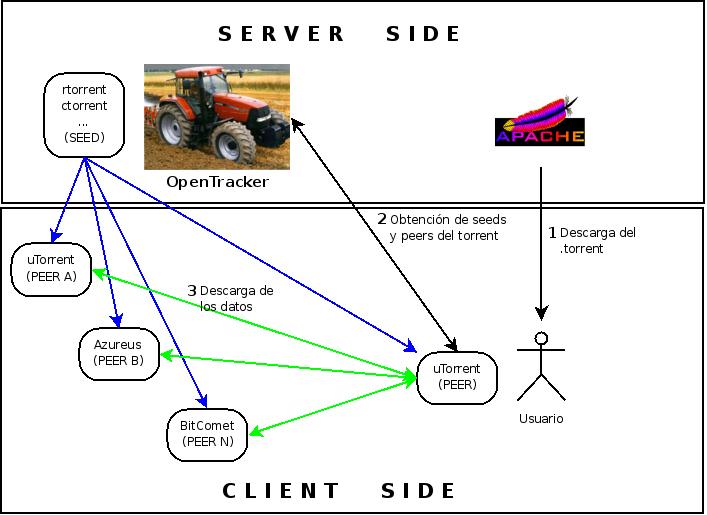
Y para el campeón que haya llegado hasta aquí, he hecho un pequeño gráfico representativo del flujo que se sigue al bajar un torrent y los datos asociados al mismo. Nótese que mientras las lineas azules representan la descarga desde un seeder (una fuente con los datos al completo), las verdes representan descargas multilaterales entre los peers (fuentes con los datos incompletos). Todo esto puede darse simultáneamente, y es por ello que lo he incluido en el paso 3 y sin ningún orden específico. Evidentemente y de forma ideal, los peers llegaran a convertirse en seeds una vez tengan los datos al 100%.
Antes de despedirnos, comentar que el siguiente reto sería conseguir que los archivos se distribuyeran a través de DHT, en cuyo caso entiendo no sería necesario el uso de un tracker central que mantuviera la información de los peers y seeds. Pero para ello el cliente tiene que soportar esta característica (cosa que muchos no hacen) y algunas interacciones entre ellos no funcionan, lo cual seguramente hace más pobre la red p2p y, probablemente, también más lenta.
Actualización: aquí tenéis un nuevo fichero de inicio y configuración que tiene en cuenta aspectos adicionales como que sólo deje encenderse si no está ejecutándose ya, y que sólo trate de apagarlo si se está ejecutando :)
Comentarios (3) |
{kind=link}